Git
LINK: https://git-scm.com/
Primeiramente
Antes de começar a falar sobre Git, gostaria de dizer que este material foi criado com o intuito de ajudar as pessoas que estão começando a utilizar o Git, e não tem conhecimento nenhum sobre a ferramenta. Este material tem uma sequência de passos, para que você possa entender o que é o Git, como funciona, e como utilizar seus comandos com exemplos práticos, evoluindo comando em comando.

Bora estudar!
Introdução
Git, para alguns um sonho, para outros um pesadelo, por que isso? Vamos entender o que é Git, para que é usado, como configurar, além de ver quais são os principais comandos e tudo o que você precisa para começar a utilizar essa ferramenta incrível.
Na minha opinião, o Git é a ferramenta mais importante que você deve aprender como um desenvolvedor/profissional da área de TI, pois em muitas vagas de emprego é visto como um dos requisitos mínimos. Não consigo imaginar uma empresa de software que não utiliza Git hoje em dia.
Hoje (2023) o Git é a ferramenta mais utilizada para versionamento de código, mas não é a única, existem outras ferramentas como: SVN, Mercurial, CVS.

Logo do Git
Futuramente em outro tópico será abordado a fundo o que são os sites como GitHub, GitLab, Bitbucket entre outros. Porém, o principal ponto que temos que ter em mente é que esses sites são serviços que armazenam o código do projetos que utiliza o Git como versionamento, mas nada impede que você utilize o Git sem utilizar esses sites.
O que é Git?
No site oficial do Git tem a seguinte definição:
Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency.
Em uma tradução livre seria algo como:
Git é um sistema de controle de versão distribuído gratuitamente e de código aberto projetado para lidar com tudo, desde projetos pequenos a muito grandes com velocidade e eficiência.

Vamos entender o que está escrito, analisando algumas palavras-chave da frase:
- Sistema de controle de versão: O Git é um SCM, Source Code Management (Sistema de Controle de Código Fonte). Um dos seus principais recursos é o versionamento de código, salvando quem, quando e o que foi alterado conforme seu software for evoluindo.
- Distribuído: Representa que ele funciona de forma independente, não necessita conexão com a internet, e nem que precisa de um servidor central para funcionar, cada máquina que tem o Git instalado, pode enviar alterações para as outras máquinas.
- Gratuito e de código aberto: Segundo seu criador, "Esta é a única maneira certa de se fazer software", um software que todos podem ver e contribuir com o projeto através do código fonte aberto, e o melhor, de graça.
- Projetos pequenos e muito grandes com velocidade e eficiência: Diz respeito a performance do Git, pois ele foi criado para ser rápido, e aguentar aplicações com milhares de linhas de código, como o Kernel do Linux.
Todas essas palavras-chave foram requisitos mínimos impostos quando o projeto do Git foi criado, e é seguido isto até hoje. Mas não se preocupe, você não precisa saber tudo isso para começar a utilizar o Git, são só informações complementares.
História resumida
Caso queira pular está parte histórica, pode ir direto para a instalação.
Seu criador é nada menos que Linus Torvalds, criador do Kernel Linux, do qual utilizava um outro programa de SCM, antes de existir o Git, o BitKeeper. Porém a empresa que criava o BitKeeper decidiu mudar a licença desse programa, que era gratuito e passou a ser um programa pago. Linus se negou a ter que pagar por um programa, e foi em busca de um substituto. Em sua procura, todas as opções de programas não atendiam aos seguintes requisitos:
- Gratuito
- Distribuído
- Performático
- Garantir que o que for salvo, possa ser baixado igual a forma que foi salvo.
Todos esses pontos podem ser visto no video abaixo aos 10:23.
Essa busca resultou em nenhum programa. Nas palavras do Linus "O resultado final foi que eu decidi que posso escrever algo melhor do que qualquer coisa lá fora em duas semanas, e eu estava certo" essa frase foi dita durante uma palestra dentro do Google, que pode ser vista no video abaixo, aos 12:15.
Eu falei que era resumido, mas basicamente o Git utiliza uma ferramenta do linux, o diff, está ferramenta gera a diferença entre dois arquivos, como isso ele já tinha pronto no Linux, bastava criar uma forma de salvar essas diferenças e organizar isso em uma árvore com a referência dos arquivos.
Caso tenha interesse em ver a palestra do Linus no Google, ela esta em inglês, mas você pode ativar as legendas caso necessário.
Instalação
Vamos começar a utilizar o Git, para isso, instale-o e sua máquina, acesse o site oficial do Git, e baixe a versão para o seu sistema operacional. Não vou entrar em detalhes de como instalar, pois é bem simples, basta seguir o instalador. Caso tenha dúvidas, dê uma pesquisada no Google ou YouTube, que vai terão vários tutoriais.
Para verificar se foi instalado corretamente, abra o terminal, e digite o seguinte comando:
git --version
Caso apareça a versão do Git, significa que foi instalado corretamente.

Exemplo de saída do comando git --version da versão para Windows
Caso não apareça a versão ou apresente erro ao rodar o comando, pode ser que o Git não foi instalado corretamente ou não foi adicionado ao PATH do sistema. Tente reinstalar o Git, e caso não funcione, tente pesquisar no Google ou YouTube, é bem provável que alguém já tenha passado por isso.

Erros acontecem, não desista!
Pontos importantes
Agora que temos o Git instalado, tem alguns itens que considero importantes entender antes de começarmos a sair rodando comandos, são eles:
Configuração inicial (.gitconfig)
Alguns comandos do Git precisam de algumas informações, como por exemplo, o seu nome e e-mail, para identificar quem fez as alterações no código. Para isso, vamos utilizar o seguinte comando:
git config --global user.name "Seu nome"
git config --global user.email "seu_email@email.com"

Exemplo de saída dos comandos git config user.name e git config user.email
A opção --global serve para informar que essa configuração é global, ou seja, ela vale para todos os projetos que você utilizar o Git. É a opção mais utilizada. O Nome não precisa ser o seu nome completo, pode ser um apelido, ou até mesmo um nome de usuário, o importante é que você se identifique. O e-mail deve ser o mesmo que você utiliza para se cadastrar em sites, pois é com ele que o Git vai identificar quem fez as alterações.
Ao rodar esses comandos, um arquivo chamado .gitconfig é criado na pasta do usuário, que é onde o Git salva as configurações globais. Você pode editar esse arquivo manualmente, mas tenha cuidado.
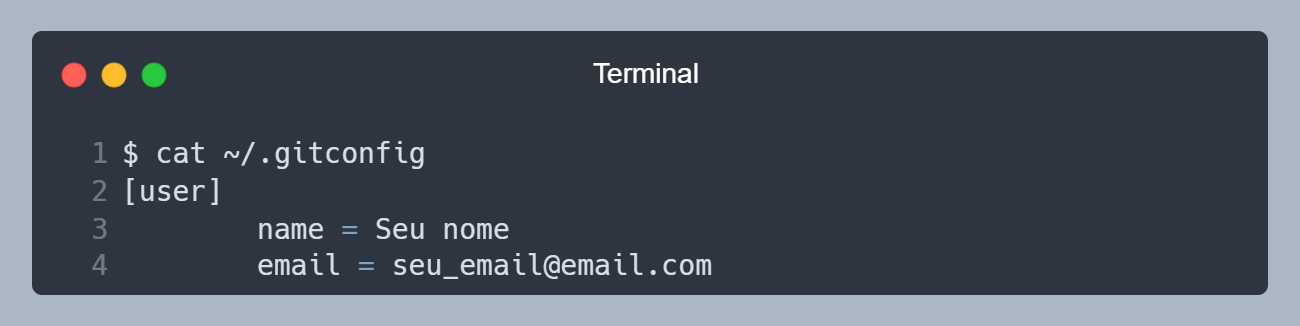
Arquivo .gitconfig gerado após rodar os comandos de configuração
Se rodarmos o comando que utilizamos para configurar o nome e e-mail, mas sem passar nenhum parâmetro, ele vai mostrar o que está configurado no momento. Que tem que bater com o arquivo .gitconfig.
git config user.name
git config user.email
Pasta .git
Toda vez que utilizamos o Git em um projeto, ele cria uma pasta oculta chamada .git, que é onde ele salva todas as informações do projeto, como as alterações feitas, histórico de ajustes, quem alterou o que, etc. Essa pasta não deve ser modificada manualmente, pois pode corromper o funcionamento do Git, a menos que você saiba o que está fazendo.
Caso esteja começando a utilizar o Git em um projeto, e não tenha essa pasta, basta utilizar o comando git init, que ele irá criar essa pasta.
Se você clonar um projeto que já utiliza o Git, essa pasta já estará criada, e você não precisa utilizar o comando git init.
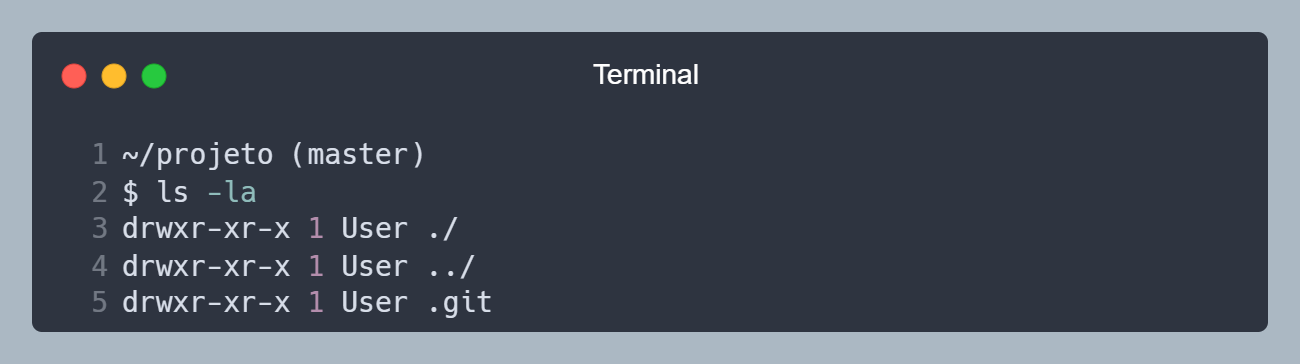
Pasta oculta .git criada após utilizar o comando git init
Arquivo .gitignore
O arquivo .gitignore é um arquivo que serve para ignorar arquivos e pastas que não devem ser monitorados pelo Git, como por exemplo, arquivos de configuração, arquivos de log, arquivos de cache, etc.
Alguns frameworks e linguagens já possuem um arquivo .gitignore padrão, que você pode utilizar, mas caso não tenha, você pode criar um arquivo .gitignore na raiz do projeto, e adicionar os arquivos e pastas que você quer ignorar.
Não é obrigatório ter um arquivo .gitignore, mas é recomendado, pois assim você não vai ficar enviando arquivos desnecessários para o repositório remoto. Torna o projeto mais limpo e organizado.
Não vamos entrar em detalhes sobre esse arquivo aqui, mas você pode ler mais sobre ele nessa página.
Ciclo de vida do Git
Os arquivos tem um ciclo de vida dentro do Git, pode parecer confuso no começo, mas é bem simples. Agora vamos só ver quais são as etapas que um arquivo pode estar, e mais a frente vamos ver que comando faz cada etapa.
Os arquivos podem estar em "quatro" etapas, sendo elas:
- Untracked (Não rastreado): Arquivos que o Git não sabe que existe. De certa forma, essa etapa não é um status do Git, pois ele não sabe que esse arquivo existe, mas é importante saber que existe essa etapa.
- Unmodified (Não modificado): Arquivos que o Git sabe que existe, mas não foi modificado. No dia a dia, a maioria dos arquivos vão estar nessa etapa.
- Modified (Modificado): Arquivos que o Git sabe que existe e que foi modificado, mas ele não está controlando as alterações feitas.
- Staged (Preparado): Arquivos que o Git sabe que existe, que foi modificado e que está preparado para o Git controlar as alterações feitas.
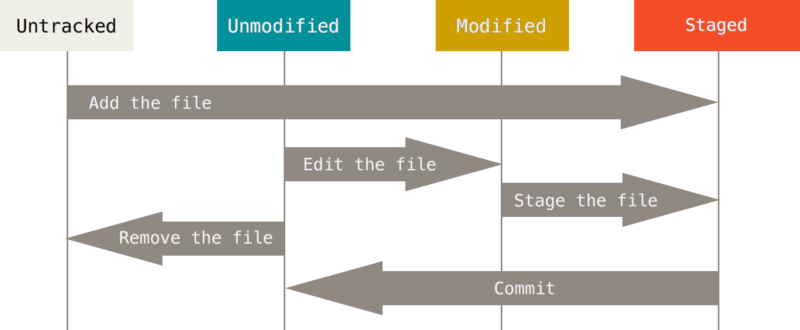
Representação do ciclo de vida dos arquivos
Fonte: Git
O Git não rastreia as alterações de todos os arquivos de forma automática, você tem que informar para ele quais arquivos ele deve monitorar. Mais a frente vamos ver como fazer isso.

Anotado!
Exemplo prático Ⅰ
Agora vamos fazer um exemplo prático, para entendermos melhor como funciona o Git. Vamos rodar alguns comandos, e ver o que acontece com cada comando. Se quiser, pode fazer esse exemplo na sua máquina e acompanhar o que acontece.
Em uma pasta vazia, abra o terminal e siga os passos abaixo.
Você pode utilizar o comando git status a qualquer momento para saber em que status do ciclo de vida seu projeto está, este comando é informativo e não modifica nada, então pode rodar a vontade.
1. Inicializando o Git
Iniciamos o Git no projeto, utilizando o comando git init. Abra o terminal na pasta do projeto, e rode o comando.
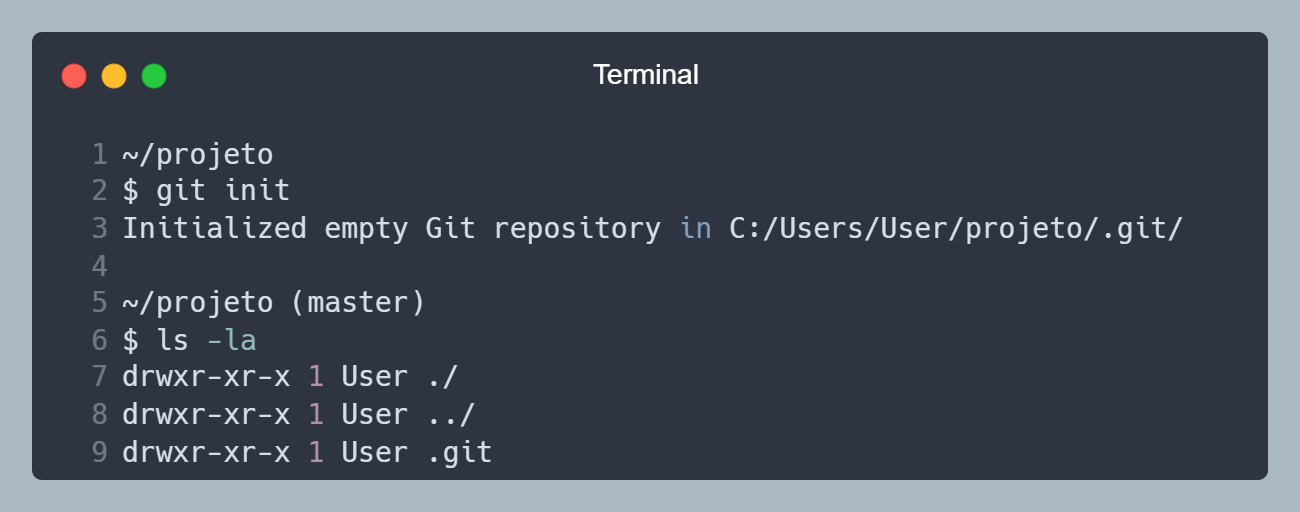
Pasta oculta .git criada após utilizar o comando git init
2. Criando um arquivo
Vamos criar um arquivo chamado index.html, deixe ele vazio por enquanto, podemos criar rodando no terminal o comando touch index.html. Para o Git, esse arquivo está na etapa Untracked, pois ele não sabe que esse arquivo existe. Podemos confirmar isso rodando o comando git status.
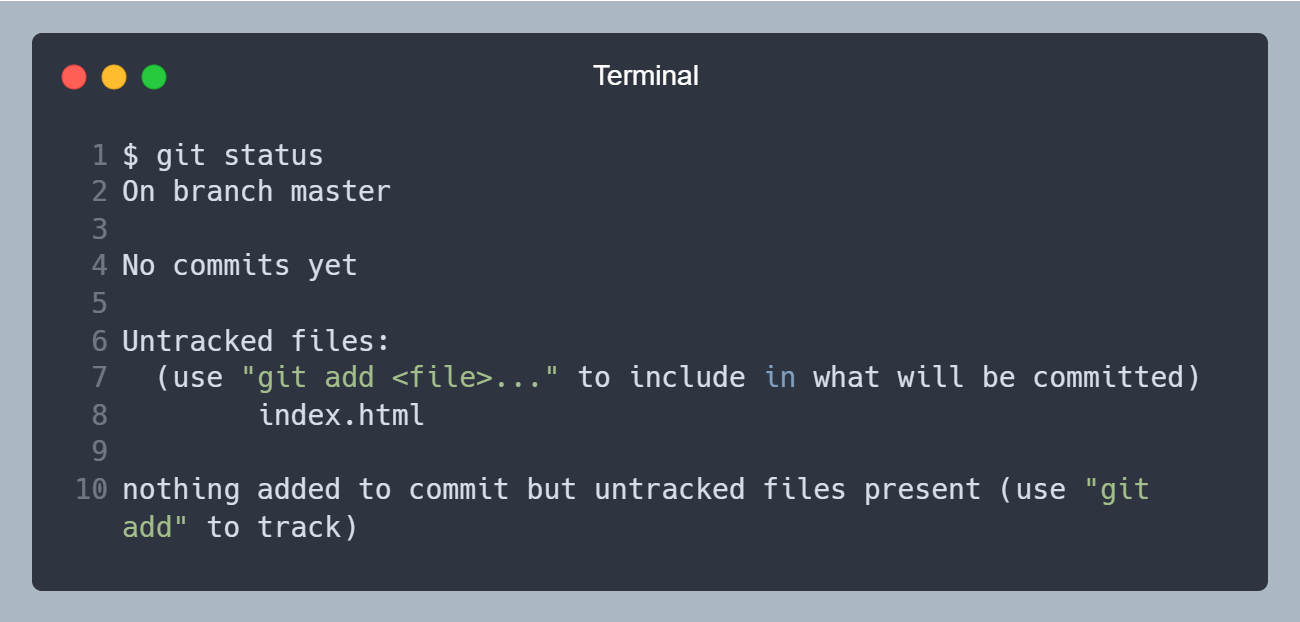
Arquivo index.html, na linha 8, listado como Untracked (Não rastreado)
3. Adicionando o arquivo para ser monitorado
Adicionamos o arquivo index.html para ser monitorado pelo Git, utilizando o comando git add index.html, isso vai fazer o arquivo ir para Staged (Preparado). Agora o Git está preparado para controlando as alterações do arquivo index.html. Podemos confirmar isso rodando o comando git status.
Quando o arquivo está Staged, o Git tira uma foto 📸 do arquivo e compara com a versão anterior, e salva essa "foto" 🖼️ em um local seguro, dentro da pasta .git.
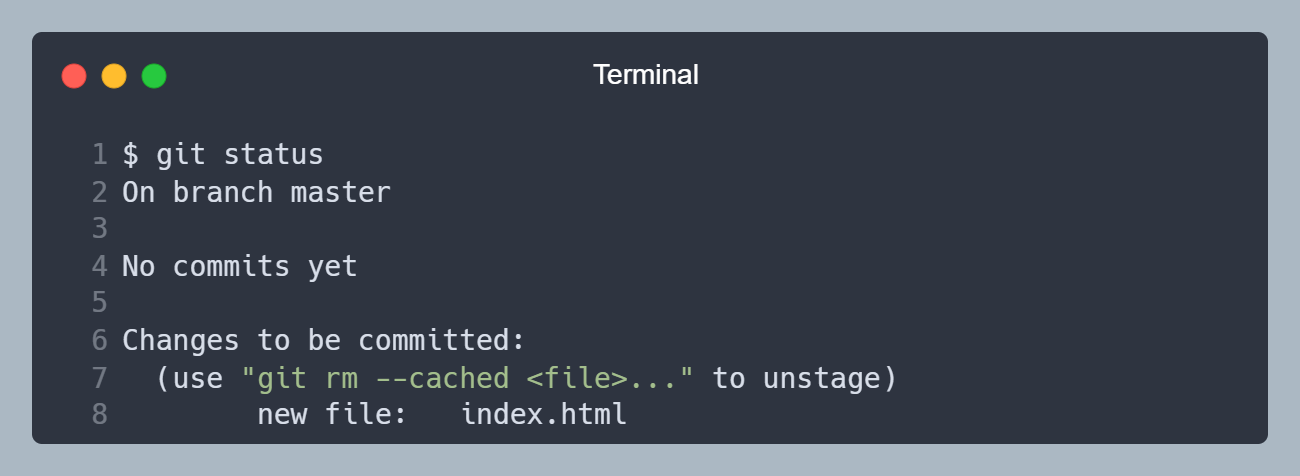
Arquivo index.html, na linha 8, na etapa Staged
4. Realizando o commit
Vamos salvar as alterações do arquivo index.html, utilizando o comando git commit -m "Atividade prática - 1".
O comando git commit pega a foto 🖼️ (que foi tirada quando o arquivo estava Staged) e salva em um local seguro, dentro da pasta .git. O commit tem informações de identificação das alterações, como os arquivos alterados, data, hora, autor e cria um hash para identificar esse commit de forma única.
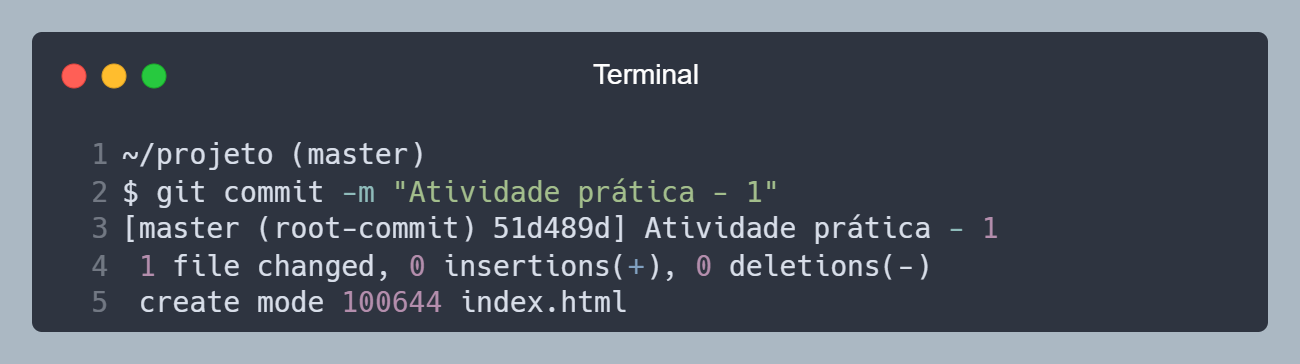
Commit de hash "51d489d" criado.
5. Verificando o status
Passamos por todas as etapas do ciclo de vida do Git. Se rodarmos o comando git status, ele vai mostrar que não tem mais nada para ser comitado, pois o arquivo index.html está na etapa Unmodified (Não modificado).
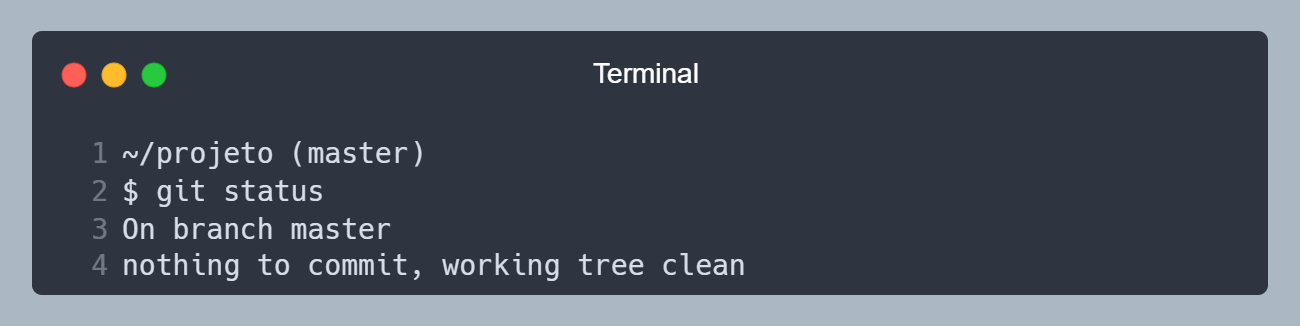
Nada para ser comitado, arquivo index.html na etapa Unmodified
Revisão
Nesse exemplo, no item 1 fizemos a inicialização do Git na pasta. No item 2 criamos o arquivo index.html, que no inicio era um arquivo que o Git não sabia que existia, então ele estava na etapa Untracked. No item 3 adicionamos o arquivo index.html para ser monitorado pelo Git, então ele foi para a etapa Staged. No item 4 realizamos o commit do arquivo index.html, então ele foi para a etapa Unmodified. Assim passamos por todas as etapas do ciclo de vida do Git.

Parabéns, você passou por todas as etapas do ciclo de vida do Git!
Exemplo prático Ⅱ
Vamos seguir com o mesmo exemplo, mas agora vamos fazer algumas alterações no arquivo index.html, e ver como o Git se comporta.
6. Alterando o arquivo
Vamos adicionar um conteúdo no arquivo index.html, pode ser qualquer coisa, mas vamos adicionar o seguinte conteúdo:
<h1>Olá mundo</h1>
7. Verificando o status
Agora vamos rodar o comando git status, para ver em que etapa o arquivo index.html está. Ele vai mostrar que o arquivo está na etapa Modified (Modificado), pois o Git sabe que o arquivo existe, mas não está monitorando as alterações.
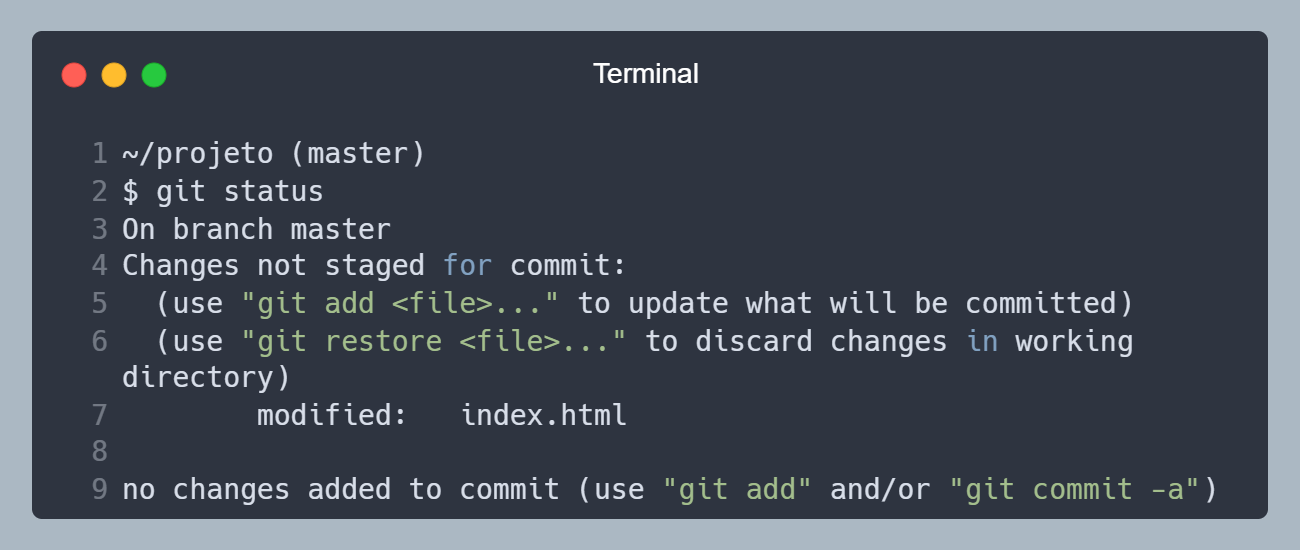
Arquivo index.html, na linha 7, na etapa Modified
8. Adicionando o arquivo para ser controlado
Vimos na etapa 3 que falamos para o Git começar a monitorar o arquivo index.html, e ele foi para a etapa Staged. Agora vamos rodar o comando git add index.html novamente, para o Git tirar uma nova foto 📸 do arquivo, preparando ele para ser salvo as alterações.
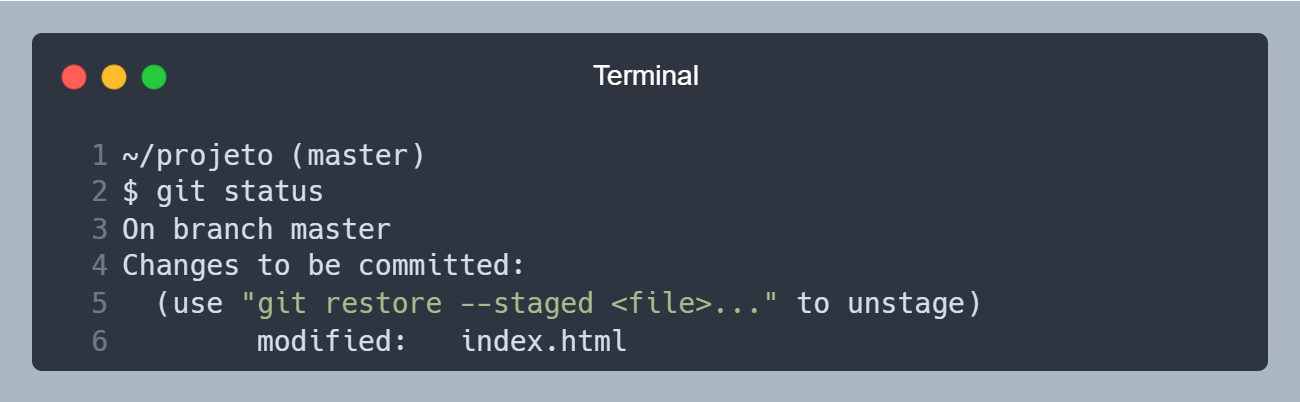
Agora a mensagem fala que tem um arquivo modificado, e que está pronto para ser comitado.
9. Realizando o commit
Agora vamos salvar as alterações do arquivo index.html, utilizando o comando git commit -m "Adicionando o conteúdo Olá mundo". O Git vai tirar uma nova foto 🖼️ do arquivo, e salvar em um local seguro, dentro da pasta .git.
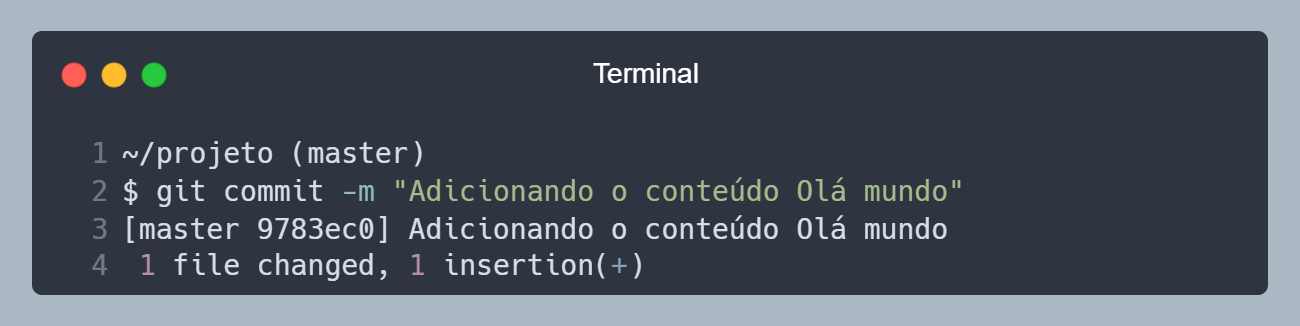
Commit de hash "9783ec0" criado.
10. Verificando o status
Agora vamos rodar o comando git log, para ver o histórico de commits que fizemos. Ele vai mostrar o hash do commit, a mensagem que foi passada, o autor, a data e hora, e o arquivo que foi alterado.
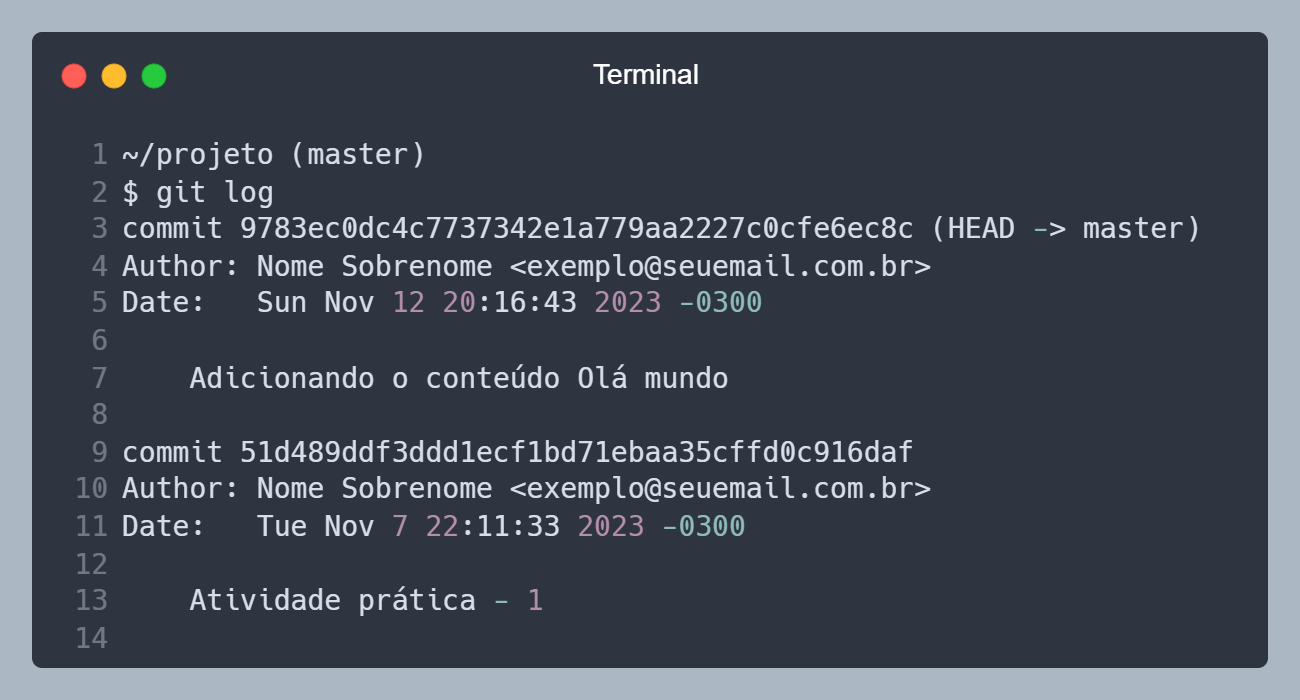
Histórico de commits.
Revisão
Nesse exemplo, no item 6 alteramos o arquivo index.html, que estava na etapa Unmodified, então ele foi para a etapa Modified. No item 7 adicionamos o arquivo index.html para ele ficar preparado para o Git controlar as alterações, então ele foi para a etapa Staged. No item 8 realizamos o commit do arquivo index.html, então ele foi para a etapa Unmodified. Assim passamos por todas as etapas do ciclo de vida do Git novamente.
Conclusão
Os exemplos foram bem simples, mas representam bem o dia a dia de um desenvolvedor, que é alterar arquivos, e salvar as alterações. O Git é uma ferramenta muito poderosa, e que pode ser utilizada de diversas formas, mas o básico é isso, e com isso você já consegue utilizar o Git no seu dia a dia.
Repositório remoto
Agora que já sabemos como funciona o Git localmente, vamos ver como funciona o Git em um servidor remoto. O servidor remoto é onde o projeto fica hospedado, e onde você e seus colegas vão baixar o projeto, e enviar as alterações.
Os principais servidores remotos são o GitHub, GitLab e Bitbucket. Não vamos entrar em detalhes sobre cada um deles. Não importa qual você vai utilizar, o Git funciona da mesma forma em todos eles.
Configurando o repositório remoto
Para configurar o repositório remoto, vamos utilizar o comando git remote add origin <URL>, onde <URL> é a URL do repositório remoto. Por exemplo, o projeto que estamos utilizando nesse guia, está hospedado no GitHub, então a URL do repositório é https://github.com/lucasbaccan/code.git ou a versão com SSH git@github.com:lucasbaccan/code.git.

Configurando o repositório remoto.
No exemplo acima, o nome do repositório remoto é origin, mas você pode dar o nome que quiser, mas o nome origin é o padrão, e é o mais utilizado.
Você pode configurar mais de um repositório remoto, não é algo muito comum, mas é possível. Para isso, basta utilizar o comando git remote add <NOME> <URL>, onde <NOME> é o nome do repositório remoto, e <URL> é a URL do repositório remoto.
Enviando as alterações para o repositório remoto
Agora que já configuramos o repositório remoto, vamos enviar as alterações que fizemos localmente para o repositório remoto. Para isso, vamos utilizar o comando git push <NOME> <BRANCH>, onde <NOME> é o nome do repositório remoto, e <BRANCH> é o nome da branch que queremos enviar as alterações.
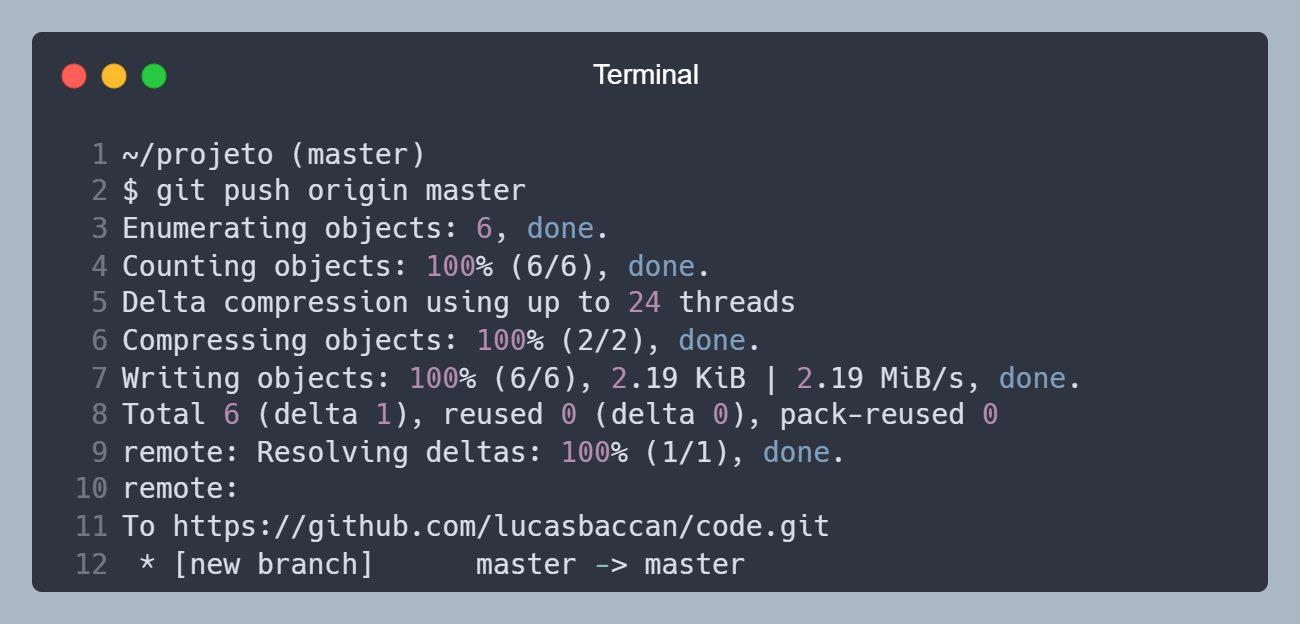
Enviando as alterações para o repositório remoto.
Baixando as alterações do repositório remoto
Agora vamos baixar as alterações que foram feitas no repositório remoto, para isso, vamos utilizar o comando git pull <NOME> <BRANCH>, onde <NOME> é o nome do repositório remoto, e <BRANCH> é o nome da branch que queremos baixar as alterações.
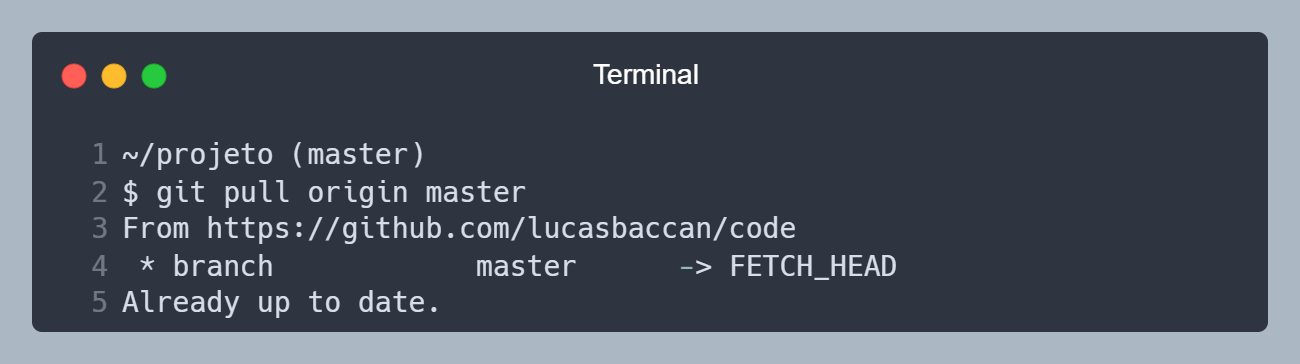
Baixando as alterações do repositório remoto.
No exemplo acima, o comando git pull origin master baixou as alterações da branch master do repositório remoto origin e colocou na branch master local.
O comando git pull é uma junção dos comandos git fetch e git merge, então ele baixa as alterações do repositório remoto, e faz o merge com a branch local.
Você pode utilizar os comandos git fetch e git merge separadamente sem problemas, mas o git pull é mais prático.

Parabéns, você aprendeu como trabalhar com o Git localmente e com um repositório remoto!
Branches(Ramificações)
Uma das funcionalidades mais importantes do Git é a possibilidade de criar branches (ramificações). As branches são ramificações do projeto, que podem ser utilizadas para diversas finalidades, como por exemplo, criar uma nova funcionalidade, corrigir um bug, testar uma nova versão, etc.
Com isso você pode trabalhar em uma nova funcionalidade, sem afetar o projeto principal, e quando estiver tudo pronto, você pode juntar as alterações da branch com o projeto principal, sem afetar o que já foi feito.
Criando uma nova branch
Para criar uma nova branch, vamos utilizar o comando git checkout -b <NOME>, onde <NOME> é o nome da branch que queremos criar. Por exemplo, vamos criar uma branch chamada feature/nova-funcionalidade, então vamos rodar o comando git checkout -b feature/nova-funcionalidade.
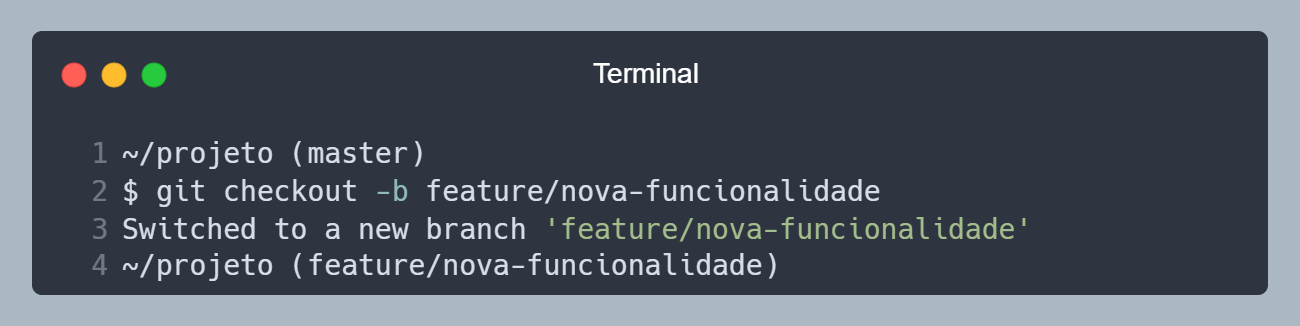
Criando uma nova branch chamada feature/nova-funcionalidade.
Trocando de branch
Para trocar de branch, vamos utilizar o comando git switch <NOME>, onde <NOME> é o nome da branch que queremos trocar. Por exemplo, vamos trocar para a branch master, então vamos rodar o comando git switch master.
O comando git switch foi adicionado na versão 2.23 do Git, então se você estiver utilizando uma versão anterior, utilize o comando git checkout <NOME>.
Eu ainda utilizo o padrão antigo, ambos funcionam da mesma forma, mas o git switch é mais intuitivo.
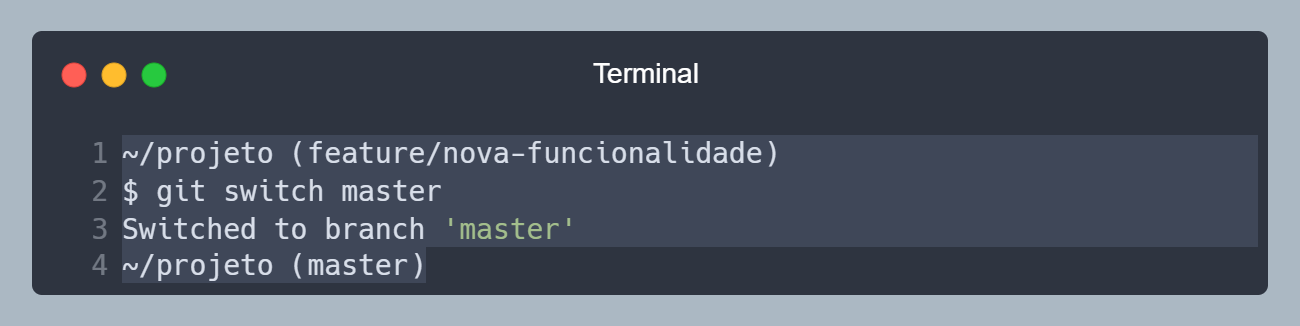
Trocando para a branch master.
Se você fez alguma alteração na branch feature/nova-funcionalidade, e tentar trocar para a branch master, o Git vai mostrar uma mensagem de erro, pois você tem alterações que não foram salvas. Então você tem duas opções, salvar as alterações, ou descartar as alterações.
Se você for salvar as alterações, basta rodar o comando git commit -m "Mensagem do commit", e depois rodar o comando git switch master novamente. Assim as alterações serão salvas na branch feature/nova-funcionalidade, e você vai conseguir trocar para a branch master.
A branch master NÃO vai ter as alterações que você fez na branch feature/nova-funcionalidade, pois as branches são independentes.
Juntando as alterações de uma branch com outra
Agora que já sabemos criar e trocar de branches, vamos ver como juntar as alterações de uma branch com outra. Para isso, vamos utilizar o comando git merge <NOME>, onde <NOME> é o nome da branch que queremos juntar. Por exemplo, vamos juntar as alterações da branch feature/nova-funcionalidade com a branch master, então vamos rodar o comando git merge feature/nova-funcionalidade.
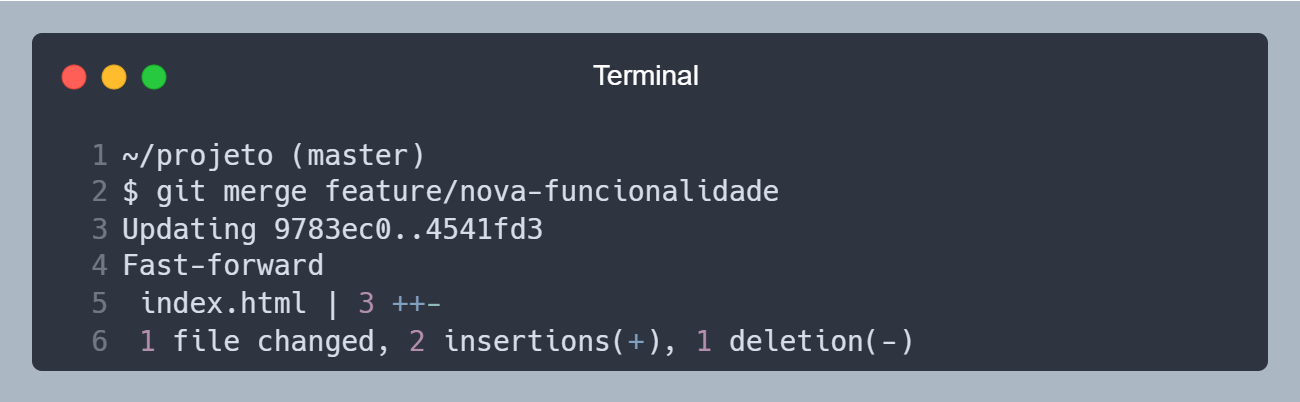
Juntando as alterações da branch feature/nova-funcionalidade com a branch master.
Com isso, as alterações da branch feature/nova-funcionalidade foram juntadas com a branch master, e agora a branch master tem as alterações da branch feature/nova-funcionalidade.
Caso você deseja fazer o merge de uma branch remota com uma branch local, basta utilizar o comando git merge <NOME>, onde <NOME> é o nome da branch remota que queremos juntar. Por exemplo, vamos juntar as alterações da branch origin/feature/nova-funcionalidade com a branch master, então vamos rodar o comando git merge origin/feature/nova-funcionalidade.
Resumo
O que vimos até agora foi:
- Criar uma nova branch com o comando
git checkout -b <NOME>. - Trocar de branch com o comando
git switch <NOME>. - Juntar as alterações de uma branch com outra com o comando
git merge <NOME>.
No exemplo sobre merge, utilizamos o nome origin antes do nome da branch, pois a branch feature/nova-funcionalidade é uma branch remota, e não uma branch local. Lembre-se que no git temos branches locais e branches remotas que são independentes.

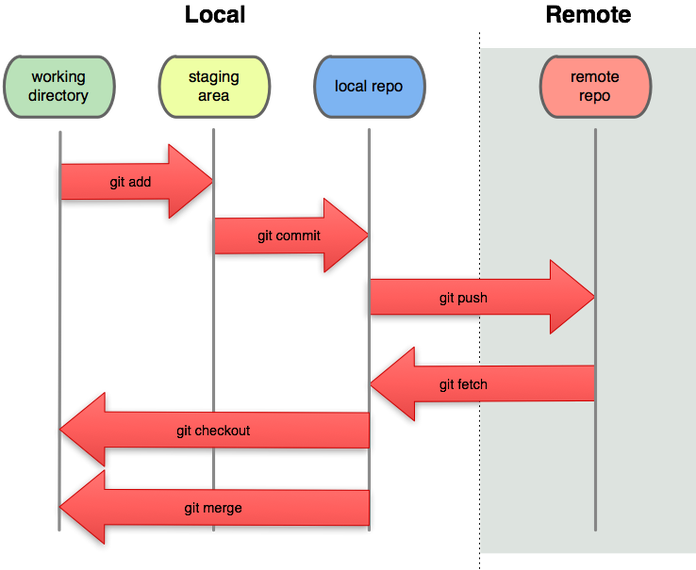
Fluxo de trabalho com branches locais e remotas.
- Diretório local: Pasta na qual você utiliza para programar, onde seu projeto está.
- Stage (INDEX): Arquivos modificados que foram indexados pelo git.
- Repositório Local (HEAD): Cópia do repositório remoto em seu dispositivo.
- Repositório Remoto: Servidor onde o projeto está hospedado.
CLI
O termo CLI significa Command-Line Interface (Interface de Linha de Comandos). Acho que esta parte assusta um pouco as pessoas, pois o Git não tem uma interface gráfica, então todas as suas ações tem que rodar por linha de comando. Existe no mercado alguns programas que funcionam com Git e disponibilizam uma interface gráfica, mas não é necessário, pode parecer complicado no início mas não é.
Se você nunca teve experiência com Terminal (Linux/MacOS) ou CMD/Powershell (Windows), não tenha medo, é mais fácil do que parece.

git init
O comando git init é onde tudo começa, você precisa rodar esse comando em um diretório para fazer com que o Git comece a gerenciar os arquivos, pastas e subpastas.
Após rodar o comando git init, vai ser criada uma pasta chamada .git, dependendo da configuração do seu sistema operacional, você não vai ver esta pasta, mas basta rodar ls -la, que é o comando para listar arquivos ocultos.
- Linha 2 - Comando
git initrodado para iniciar o diretório para ser rastreado pelo Git. - Linha 6 - Comando
ls -lapara listar os arquivos, a linha 7 e 8 são padrão do sistema e linha 9 é a pasta .git criada.
No geral, não mexa na pasta .git, dependendo do que mexer dentro desta pasta, você pode corromper a estrutura.
git status
Agora que temos um diretório .git. Podemos rodar os outros comandos do Git. Usamos o git status para saber como está a situação dos arquivos em nosso diretório local, se tem algo alterado, novo, deletado, etc.
Eu gosto de utilizar git status -s que traz de uma forma resumida, na minha visão é mais prático para identificar as alterações.
Quando rodar esse comando, ele trará algumas informações sobre os arquivos:
- Untracked ou U: Arquivos novos que não estão indexados, o git ainda não tem conhecimento deles.
- New ou A: Arquivo foi indexado, git passa a gerenciar suas alterações.
- Modified ou M: Arquivo que já era indexado pelo git e foi modificado.
- Deleted ou D: Arquivo que já era indexado pelo git e foi deletado.
- Renamed ou R: Arquivo que já era indexado pelo git e foi renomeado.
git add
Este comando tem o propósito de adicionar o arquivo ou pasta para o stage, isso significa que você quer salvar no git as alterações que foram feitas neste arquivo.
Esta ação sozinha não faz nada, mas sem ela, você não pode fazer um commit, então, após realizar as alterações que deseja no seu projeto (criar arquivos, renomear, alterar o conteúdo do arquivo), utilize git add . para adicionar todos os arquivos, ou git add menu.txt para adicionar o arquivo menu.txt no stage.
git commit
No passo anterior vimos como adicionar um arquivo no stage, agora veremos como fazer com que essas alterações sejam enviadas para nosso repositório local. Para isso utilizamos git commit, a forma que gosto de explicar é "Pegar as alterações e adiciona numa caixinha(commit) que depois vai ser enviada para o remoto" .
O commit tem a relação de quais arquivos tem que ser enviados, o que mudou entre a versão anterior e a atual, o autor das alterações, data, etc. Utilize git commit -m "Primeiro Commit", O parâmetro -m é a mensagem que vai ser anexado ao commit. É uma boa prática adicionar uma descrição do que foi alterado.
git push
Seguindo o que fizemos até agora, nós adicionamos uma alteração, criamos um commit, então falta enviar essa alteração para o repositório remoto, para isso utilizamos git push.
Para o comando funcionar corretamente, temos que falar qual repositório remoto vamos utilizar e para qual branch enviaremos.
git push origin master
O comando acima envia todos os commits do branch atual que estão em seu repositório local para o repositório remoto, nesse caso, o nome do repositório remoto é origin, e o branch é o master.
git fetch
Utilize esse comando para puxar as alterações remotas para seu repositório local. Você deve obrigatoriamente informar qual é o repositório remoto do qual deseja pegar as alterações.
# puxar todas as alterações do repositório remoto
git fetch origin
# ou pode especificar um único branch e buscar só as alterações dele
git fetch origin master
O comando acima puxa todos os commits do repositório remoto origin, e no segundo caso filtra somente alterações do branch.
git merge
O comando git fetch busca as alterações remotas, mas para aplicá-las em seu diretório local, você tem que fazer o merge delas, para isso, utilize git merge. Você pode sincronizar alterações do branch atual que está ou outro branch.
git merge origin/master
# ou fazer o merge de um branch local
git merge master
Parece que os dois comandos são iguais, mas quando utilizamos origin/master, você está especificando que quer o branch master do repositório remoto, que você fez o fetch anteriormente. Quando utilizamos master, você está especificando que quer o branch master do repositório local.
git pull
Esse carinha aqui podemos fazer que é a combinação de dois outros métodos que vimos anteriormente, o git fetch e o git merge. Basicamente o git pull ele faz os dois comando em um só, puxa as alterações e faz o merge no diretório local
git pull origin master
git reset
Até o momento vimos o caminho perfeito, mas se fizer 💩, o que o git pode fazer por nós, meros mortais? Para isso, temos o git reset, que desfaz as alterações.
Vamos com calma nessa parte, pois dependendo dos parâmetros que utilizar com git reset você pode perder alterações em seu código, então vamos ver elas e entender melhor.
Um dos parâmetros que temos é o --soft, ele vai voltar somente os commits do seu diretório local, mas vai manter as alterações nos arquivos.
git reset --soft origin/master
# ou
git reset origin/master
Mas se o que você quer é apagar tudo que fez, até mesmo os commits, utilize --hard, ele afeta seu diretório local e repositório local.
git reset --hard origin/master
git checkout
Muito utilizado no dia a dia, utilizamos git checkout para mudar o conteúdo do nosso diretório local. Imaginamos que eu tenho os seguintes branches: master, dev e test. Se eu quero mudar meu ambiente para fazer uma nova funcionalidade, e não quero afetar meu código no master, utilizar git checkout dev para mudar para um branch que já existe.
Caso eu queira criar um novo branch, posso utilizar git checkout -b fix1 para criar um branch novo chamado fix1.
git switch
Esse comando é bem parecido com o git checkout, mas ele é mais intuitivo, e foi adicionado na versão 2.23 do Git. Então se você estiver utilizando uma versão anterior, utilize o comando git checkout <NOME>.
git switch dev
# ou
git switch -c fix1 # cria um novo branch chamado fix1
git rebase
O comando git rebase é um pouco mais avançado, mas é muito útil, ele serve para reescrever o histórico de commits, ou seja, você pode alterar a ordem dos commits, juntar commits, deletar commits, etc.
git rebase -i HEAD~3
O comando acima vai abrir um editor de texto, e vai mostrar os últimos 3 commits, e você pode fazer as alterações que desejar.
git tag
O comando git tag é utilizado para marcar um ponto específico do histórico do projeto, geralmente é utilizado para marcar uma versão do projeto.
git tag -a v1.0.0 -m "Versão 1.0.0"
O comando acima vai criar uma tag chamada v1.0.0 e vai adicionar uma mensagem Versão 1.0.0.
Comandos utilizados com menos frequência
git clone
Você tende a utilizar isso uma vez e pronto, você informa um repositório remoto e copia ele para sua máquina. Se for um repositório privado, vai ser solicitado usuário e senha, caso contrário, o clone acontece normalmente.
git clone https://github.com/microsoft/vscode.git
# comando para clonar o projeto do VS Code, disponível no GitHub.
Eu gosto de utilizar o parâmetro -o para atribuir um nome específico para meu repositório remoto, nesse caso, o nome que for colocado substitui o origin. É raro trabalhar em um projeto com mais de um repositório remoto, mas é possível.
Exemplo: Uma empresa hipotética separou o ambiente de desenvolvimento em dois repositórios, oficial e teste. Além disso, ela não aceita que um programador envie suas alterações para o repositório oficial. Para ajudar no entendimento dos repositórios, você pode utilizar o parâmetro -o para atribuir um nome no momento do clone, como -o oficial e -o teste, então assim você pode fazer
git fetch oficialegit push teste master.
# Realizar a copia do repositório do VSCode e renomear ele como remoto
git clone https://github.com/microsoft/vscode.git -o remoto
# Caso eu queria depois puxar novas alterações, utilizo assim
git fetch remoto
# Caso for enviar alterações
git push remoto master
git remote
Ações relacionadas ao seu repositório remoto.
Para listar os repositórios que seu projeto tem. git remote -v, ele vai listar o repositório utilizado para fetch e para push.
Para adicionar um novo repositório remoto, passe o nome e o url do repositório.
git remote add origin1 https://github.com/microsoft/vscode.git
Se quiser remover o repositório, passe o nome do repositório remoto.
git remote remove origin1
git branch
O mais importante desse comando, poderia dizer que é git branch, esse comando lista os repositórios locais que você tem, e marca com um * o repositório atual.
Para listar todos os repositórios que o projeto tem, utilize git branch -a, ou se quiser só os repositórios remotos, git branch -r.
git clean
Deleta todos os arquivos que não estão indexados pelo git. Mesmo quando você dá um git reset --hard, arquivos que não tão indexados ficam. Utilize git clean para limpar esses arquivos.
Eu gosto de utilizar os parâmetros -d e -f, que força apagar os arquivos e diretórios.
git clean -df
git log
Verifique os commits do seu repositórios local, só rodar git log.
git reflog
Esse é um comando mais avançado, se algum dia você perder parte do código que você fez um git reset --hard, talvez exista a possibilidade de recuperar utilizando git reflog. No caso git reflog vai mostrar uma sequência de hash, e daí você pode utilizar esse hash para fazer um git reset hash.
Cuidados
Às vezes pode ser que seu objetivo seja forçar o envio de uma alteração, mas esse comando pode causar a perda de código permanentemente. Geralmente quando vemos um parâmetro -f temos que tomar cuidado, pois existe uma grande chance de ser F de Forçar, no caso, forçar uma alteração.
git push -f origin master
Um outro ponto para notar é que para deletarmos um branch local, utilizamos git branch -d master, entretanto, não dá para fazer push disso, então para deletar um branch remoto, basta colocar um : antes do seu nome, o que pode até acontecer por acidente na hora de digitar.
git push origin :master
Extra
Alguns links que achei interessante, se tiver um tempo, dê uma olhada.
Achei interessante a imagem, tem uma representação do fluxo de acordo com cada comando.
Parabéns
Você chegou até aqui, espero que tenha gostado do conteúdo, e que tenha aprendido algo novo. Trabalhar com Git é muito legal, e é uma ferramenta muito poderosa, que pode ser utilizada de diversas formas, e que pode te ajudar muito no seu dia a dia. Quanto mais você utilizar o Git, mais você vai aprender, e mais você vai gostar dele.

Parabéns, você aprendeu como trabalhar com o Git!
https://ohmygit.org/ https://learngitbranching.js.org/?locale=pt_BR